왜 딥러닝 (Deep Learning) 모델은 GPU에서 월등한 성능을 보일까요? CUDA 프로그래밍에 관하여 알아봅시다.
- Frank So
- 2024년 5월 6일
- 6분 분량
딥러닝 (Deep Learning)을 말할때는 대부분이 GPU를 이용하여 성능을 향상한다고 합니다.
GPU (Graphical Processing Units)는 이미지나 2D, 3D 그래픽을 렌더링 시에 성능을 향상시키기 위해 제작되었습니다. 그러나 뛰어난 병렬작업의 성능 때문에 GPU는 딥러닝 같은 다른 애플리케이션에 많이 이용이 되고 있습니다.
GPU가 딥러닝 모델에 사용이 되기 시작한 때는 2000년대 중후반이었고 AlexNet의 출현에 의해 2012년도에 매우 유명해 졌습니다. 알렉스 크리제브스키 (Alex Krizhevsky), 일리야 수츠케버 (Ilya Sutskever)와 제프리 힌튼 (Geoffrey Hinton)에 의해 만들어진 합성곱 신경망(Convolutional Neural Network, CNN)인 AlexNet은 2012년도에 대규모 시각 인식 챌린지 (ImageNet Large Scale Visual Recognition Challenge, ILSVRC)에서 수상을 하였습니다. 이러한 성공은 GPU를 이용하여 대규모의 모델을 훈련시켜 이미지 분류를 가능하게 한 딥뉴럴 네트워크의 유효성을 보여주었습니다.
이러한 발전이 있은 후, GPU는 딥러닝 모델에 자주 사용이 되어 PyTorch나 TensorFlow같은 프레임워크가 태어나는데 기여를 하게 됩니다.
이제는 PyTorch에서 .to("cuda") 코드를 사용하여 GPU로 데이터를 보내어 훈련의 성능을 높여주고 있습니다. 하지만 어떻게 딥러닝 알고리즘이 GPU의 계산 성능의 이점을 이용할까요? 이 포스팅에서는 이 부분에 관하여 알아보겠습니다.
신경망 (neural networks), CNN, RNN이나 트랜스포머 같은 딥러닝의 아키텍쳐는 행렬 (matrix)의 합과 곱 그리고 행렬 함수의 수학 계산으로 구성되어 있습니다. 그러므로 이런 계산의 최적화를 하게되면 딥러닝 모델의 성능을 개선시킬 수가 있게 되죠.
우선, 두 벡터의 합을 구하는 간단하게 예제로 시작해 보겠습니다. C = A + B.
C는 다음과 같이 구현이 됩니다:
보시다 시피 컴퓨터는 벡터상에서 각 엘리먼트의 짝을 더하면서 순차적으로 매번 반복을 합니다. 하지만 이 계산은 각각 독립성을 가지고 있죠. 각 엘리먼트의 합은 다른 엘리먼트의 합에 의존하지 않습니다. 그러면 이 계산을 동시에 모두 실행하면 어떨까요?
아주 쉽게 말하자면 CPU의 멀티스레딩을 사용하여 병렬로 계산을 하겠죠. 하지만 딥러닝은 몇백만개의 엘리먼트가 존재하는 거대한 벡터를 이용합니다. 현존하는 CPU는 보통 12개 미만의 스레드를 병렬 처리를 할 수 있습니다. 이 부분에서 GPU가 월등히 우월합니다. 모던 GPU는 보통 몇백만개의 스레드를 처리할 수 있습니다, 그러므로 이렇게 거대한 벡터의 수학 계산시 성능이 월등하게 돋보이게 됩니다.
GPU vs CPU
하나의 오퍼레이션을 실행할 때는 CPU가 GPU보다 빠를 수 있습니다. 하지만 GPU의 이점은 병렬 처리 기능입니다. 이유는 GPU는 CPU보다 다른 목적으로 만들어 졌기 때문입니다. CPU는 순차적인 계산 (스레드)을 빠르게 실행하기위해 설계가 되었습니다. 보통 12개 정도의 스레드까지 병렬 처리를 할 수 있죠. 그러나 GPU는 각 스레드의 스피드는 CPU보다 느리지만 몇백만개의 계산을 병렬로 처리할 수 있도록 설계가 되었습니다.
아래의 동영상에서 설명을 합니다:
시각화를 하자면, CPU는 빠른 페라리 (Ferrari)이고 GPU는 버스라고 생각하시면 됩니다. 하고자하는 작업이 한 사람을 옮기는 일이면 페라리 (CPU)가 확실하게 좋은 선택이죠, 그러나 여러 사람을 옮기는 일이면 페라리 (CPU)는 매회 버스 (GPU)보다 속도가 빠르겠지만, 버스 (GPU)는 한번에 모든 사람들을 옮길 수 있습니다. 그러므로 여러번 왕복해야하는 페라리 (CPU) 보다 버스 (GPU)가 월등히 더 나은 선택이죠. CPU는 순차적인 계산을 위해, GPU는 병렬 계산을 위해 설계가 되었습니다.

병렬 처리의 성능을 높이기 위하여 GPU는 데이터 캐싱이나 플로우 컨트롤용 보다는 데이터 처리용으로 더 많은 트랜지스터를 구성하고 있습니다. CPU는 반대로 싱글 스레드 성능과 복잡한 명령어의 실행용으로 더 많은 트랜지스터를 사용하도록 구성되어 있습니다.
아래의 이미지는 CPU와 GPU의 칩 리소스의 분배 구조를 보여주고 있습니다.

CPU는 파워풀한 코어와 더 복잡한 캐시 메모리 아키텍처로 구성되어 있습니다. 이러한 디자인은 순차적인 연산을 빠르게 핸들링 할수 있게 합니다. 그러나 GPU는 코어의 수를 늘려 고도화된 병렬화를 가능하게 합니다.
이로써 기본 컨셉트는 이해가 되었으므로 다음은 실제로 이런 병렬 계산 기능을 어떻게 이용하는지 알아보겠습니다.
CUDA(쿠다) 입문
딥러닝 모델을 실행할 시에는 파이썬 (Python) 라이브러리중 PyTorch나 TensorFlow를 사용하게 됩니다. 그러나 이 라이브러리의 코어는 C/C++ 코드로 이루어져 있고, 앞에서 말하바와 같이 개발시에는 GPU를 사용하여 실행속도를 개선할 것입니다. 여기에서 CUDA가 빛을 발합니다. CUDA는 Compute Unified Architecture의 약자이고 GPU의 일반적인 계산을 위해 NVIDIA에서 개발된 플랫폼입니다. 그러므로 DirectX가 그래픽 계산을 위해 게임 엔진에서 사용이 된다면, CUDA는 개발자가 NVIDIA의 그래픽 렌더링을 넘어 GPU를 이용해 일반적인 소프트웨어 애플리케이션의 계산 성능을 높이게 해줍니다.
CUDA는 GPU의 가상 명령어 세트에 접근을 가능하게 하고 CPU와 GPU의 데이터를 이동하게 하는 것과 같이 몇가지의 스페셜 연산을 가능하게 하는 C/C++ 기반의 인터페이스 (CUDA C/C++)를 제공하고 있습니다.
더 깊이 들어가기전에 기본적인 CUDA 프로그래밍 개념과 용어를 알아보겠습니다.
host: CPU와 CPU의 메모리를 가리킵니다
device: GPU와 GPU의 메모리를 가리킵니다
kernel: device (GPU) 상에서 실행되는 함수를 가리킵니다
그러므로, CUDA를 이용한 기본 코드는 host (CPU) 상에서 실행되는 프로그램이 있고, 그 프로그램이 device (GPU)로 데이터를 보내어 kernels (함수)를 device (GPU)상에서 실행합니다. 실행 후에는 결과값이 device (GPU)에서 host (CPU)로 이동이 됩니다.
두 벡터를 합하는 이전의 예제로 다시 돌아가 보겠습니다:
CUDA C/C++에서는 호출되면 N번동안 N개의 CUDA 스레드가 병렬로 실행이 되는 kernels라고 불리우는 C/C++ 함수를 지정할 수 있습니다.
kernel을 지정하려면 우선 __global__선언자를 사용하고 <<<...>>> 표기법을 이용하여 kernel을 실행할 CUDA 스레드의 개수를 다음과 같이 지정합니다:
kernel을 실행하는 각 스레드는 threadIdx라는 빌트인 변수에 유니크한 스레드 ID를 받게됩니다. 위의 예제 코드는 N의 사이즈를 가지고 있는 A와 B의 벡터를 합한 후 결과를 C의 벡터에 저장을 합니다. 보시다시피, 각각의 계산을 순차적으로 하는 것이 아니고 CUDA는 N개의 스레드를 이용하여 한번의 병렬 계산을 가능하게 해줍니다.
이 코드를 실행하기전에, 또하나의 수정을 해야합니다. kernel 함수가 device (GPU)에서 실행이 되게 하는 것이 중요한 점입니다. 그래서 모든 데이터는 device의 메모리에 저장이 되어야 하죠. 이를 위해 다음의 CUDA 빌트인 함수를 이용하게 됩니다.
A, B와 C의 변수를 kernel에 보내는 대신에 pointer를 사용해야 합니다. CUDA 프로그래밍에는 kernel 에서 호스트의 배열을 직접 사용할 수 없습니다. CUDA의 kernel은 device의 메모리에서 실행이 되므로 device pointers를 kernel에 전달해야 합니다.
게다가, cudaMalloc을 이용하여 device의 메모리를 할당해야 하고 cudaMemcpy를 이용하여 데이터를 host와 device간에 복사를 합니다.
이제는 A와 B 벡터를 초기화하고 CUDA 메모리를 코드 마지막에 새로고침을 합니다.
그리고 kernel 호출 후 cudaDeviceSynchronize();를 삽입합니다. 이 함수는 host와 device 스레드의 동기화에 사용됩니다. 이 함수가 호출되면 host의 스레드는 다음 실행을 하기 전에 CUDA의 모든 명령어가 완료가 되기까지 기다립니다.
더 나아가서는 GPU의 버그를 식별하기 위해 CUDA 오류 체크도 중요합니다. 오류 점검을 삽입하지 않으면 코드는 host의 스레드 (CPU)에서 계속 실행이 되고 CUDA에 관한 오류를 식별하기가 어렵게 됩니다.
아래의 예제 코드로 오류 점검을 합니다:
CUDA 코드를 컴파일하고 실행하기 위해서는 CUDA 툴키트가 컴퓨터에 설치되어야 합니다. 그러면 nvcc (NVIDIA CUDA Compiler)를 이용하여 코드 컴파일이 됩니다. GPU가 머신에 존재하지 않는다면 Google Colab을 이용하면 됩니다. 런타임 → 노트북 설정에 GPU를 셀렉트하고 코드를 example.cu파일로 저장후 다음의 코드를 실행하면 됩니다.
하지만 아직도 코드의 최적화가 되지 않았습니다. 위의 예제는 N=1000의 벡터의 사이즈를 사용하고 있습니다. 그러나 이 숫자는 GPU의 병렬연산 기능을 제대로 보여주지 못하죠. 게다가 딥러닝 문제는 보통 몇백만개의 파라미터가 존재하는 거대한 벡터를 사용합니다. 그러나 이 예제에서 N=500000의 벡터 사이즈와 <<<1, 500000>>>의 kernel을 이용하면 오류가 생기게 됩니다. 그러므로 이런 연산을 위해 Thread hierarchy라는 CUDA 프로그래밍의 중요한 개념을 이해해야 합니다.
Thread Hierarchy
kernel 함수를 부르는 코드는 <<<블록의_개수, 블록_당_스레드의_개수>>>의 표기를 이용합니다. 그래서 위의 예제 코드에는 1개의 블록과 N개의 CUDA 스레드를 이용하죠. 그렇지만, 각 블록 당 사용할 수 있는 스레드의 개수는 한정이 되어 있습니다. 이는 각 블록 내의 모든 스레드는 같은 스트리밍 멀티 프로세서의 코어에 위치하고 있어야하고 그 코어의 메모리 리소스를 공유해야 합니다.
이 스레드의 개수는 다음의 코드로 알 수 있습니다.
현재 Colab GPU는 블록 당 1024개의 스레드를 사용할 수 있습니다. 그러므로 스레드가 더 필요하면 블록의 개수를 늘려야 하죠. 그리고 블록은 다음과 같이 그리드 (grids)로 정리되어 있습니다.
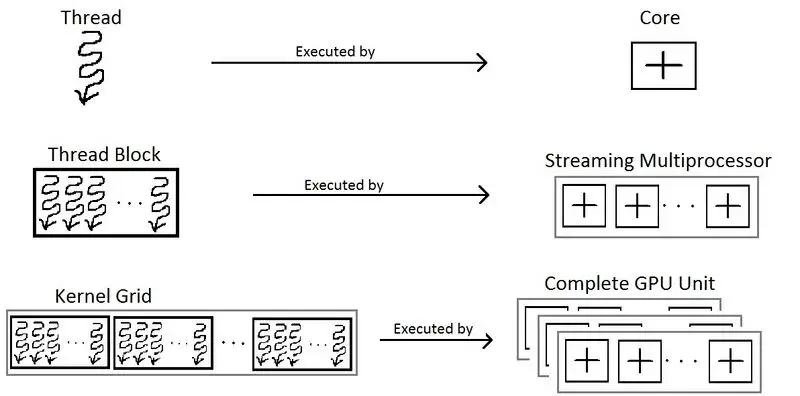
이제 스레드의 ID는 다음의 코드로 알 수 있습니다:
그러므로 완성된 예제 스크립트는 다음과 같습니다:
성능 비교
아래는 벡터 사이즈 별로 CPU와 GPU로 실행된 두개의 벡터 연산 결과를 보여줍니다.

보시다 시피, GPU의 이점은 N의 사이즈가 증가하면서 더 눈에 확실히 띕니다. 그리고 이 도표는 kernel 함수의 실행 속도만 보여주는 것이고 보통 차이는 많이 나지 않지만 host와 device간 데이터 이동 시간은 제외되었습니다. GPU 계산은 고도로 병렬화된 계산에서 이점을 보이는 것으로 보입니다.
다차원 스레드
이때까지 간단한 배열 연산의 성능은 어떻게 높이는지 알아 보았습니다. 하지만 딥러닝 모델을 다룰시에는 행렬 (matrix)과 텐서 (tensor) 연산을 다루어야 합니다. 위의 예제는 N개의 스레드를 사용하는 1차원 블록을 사용했습니다. 그러나, 3차원 까지 블록을 사용하여 실행 가능합니다. 그러므로 NxM 스레드를 가진 블록을 이용하여 행렬 연산을 할 수 있습니다. 이럴시에는 행렬의 열과 행의 인덱스를 row = threadIdx.x, col = threadIdx.y의 코드로 알 수 있습니다. 게다가 dim3 타입의 변수로 number_of_blocks 과 threads_per_block를 지정할 수 있습니다.
두 행렬의 합을 계산하는 아래의 예제를 보겠습니다.
이 예제를 여러 블록을 이용하도록 다음과 같이 확장 할수도 있습니다.
이 예제와 같은 데이터를 이용하여 3차원 연산으로 확장하여 실행할 수도 있습니다.
다차원 데이터의 연산을 실행하는 방법을 알아봤으니 이제는 또하나의 중요하지만 간단한 개념을 배워야 합니다: kernel내에 존재하는 함수를 호출하는 방법. 이 방법은 __device__ 선언자를 사용하면 됩니다. 이 선언자는 device (GPU)가 함수를 호출할 수 있게 합니다. 그러므로 __global__나 다른 __device__ 함수에서만 호출이 가능합니다.
아래 예제는 딥러닝에 자주 사용되는 벡터에 sigmoid 연산을 적용하는 예제입니다.
기본적이고 중요한 CUDA 프로그래밍의 개념을 알아 보았으니, 이젠 CUDA kernel을 개발할 수 있습니다. 딥러닝 모델에는 합, 곱, 컨벌루션 (convolution), 표준화 (normalization) 등의 행렬과 텐서 연산이 대부분입니다. 예를 들면, naive 행렬 곱 알고리즘 (naive matrix multiplication algorithm)은 다음과 같이 병렬화가 됩니다:
아래의 예제는 같은 계산을 실행하는 CPU 버전입니다:
보시다 시피, GPU버전은 loop의 개수가 더 적어서, 더 빠른 실행이 가능합니다. 아래의 도표는 CPU와 GPU 버전의 NxN 행렬 곱의 연산 실행 시간을 비교합니다.

보시다시피, GPU 버전의 성능이 행렬의 크기가 커질 수록 더 좋게 보입니다.
y = σ(Wx + b) 개의 연산을 하는 basic neural network의 예제는 다음과 같습니다.
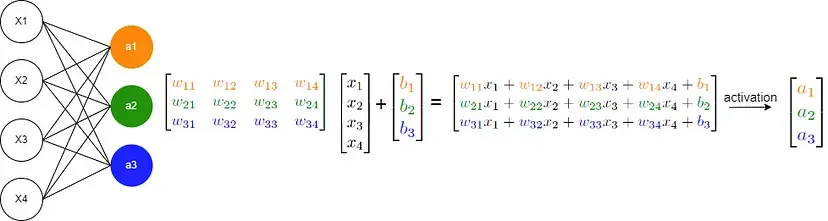
이 연산들은 행렬 곱, 합, 배열에 함수를 실행등으로 구성되어 있죠. 이 모든 것은 병렬화 기술로 가능합니다. 그러므로 이제는 GPU를 사용하는 자신만의 인공 신경망 (neural network)을 개발할 수 있겠지요?
글을 접으며
이 포스팅에서는 딥러닝의 성능을 개선하는 GPU 프로세싱의 개념을 알아 보았습니다. 하지만 이 포스팅에서 다룬 개념은 빙산의 일각에 불과 합니다. PyTorch나 Tensorflow같은 라이브러리는 최적화 메모리 액세스, 배치 연산등 더 복잡한 개념의 최적화 기술을 구현합니다. 적어도 이 포스팅을 통해 .to("cuda") 의 코드를 사용하여 딥러닝 모델을 GPU에서 실행할 시에 뒤에서 어떤 일들이 벌어지는지 조금이라도 이해가 되었으면 좋겠습니다.
참고:
